A data dictionary, also known as a codebook, provides information about the dataset variables. It is one of the most important pieces of information to include with a dataset for anyone who wants to interpret and reuse the data. Even if you are not planning on releasing your data, it is encouraged and of good data management practice to have data dictionaries for your datasets. You may know now what a variable name means in your spreadsheet (e.g., jtemp_6), but will your PI or colleagues know when you leave the lab? Will you know if you try to reuse the data two years from now? A data dictionary is a critical lab asset that ensures the data that have taken great effort and resources to acquire will not go to waste in the future due to poor documentation.
Data dictionaries can fulfill funding requirements for datasets to be accompanied with proper documentation.
The data dictionary used by the ODC is a .csv file (a comma-separated value file). Learn more about .csv files here.
The file must contain the following column names in the first row:
VariableName: * Variables (i.e. column headers) that appear in the dataset. You must include all of your dataset variables in the data dictionary.
Title: * Title is the full name of the variable when the VariableName contains abbreviations or shorthand. If the VariableName is already a complete name, you can copy and paste the VariableName into the Title entry.
Unit_of_Measure: Units for the variable (if applicable).
Description: * Definitions and descriptions of the variable. The description should explain what the variable represents in enough detail such that a reader can understand the contents of the column in the dataset.
DataType: Specify whether the variable specifically contains Numeric, Categorical, Ordinal, Date, or Free Text data.
PermittedValues: If the variable is not numeric or free text, list all possible values here (e.g. "Male, Female" for the variable "Sex"). If the variable is numeric or free text, can leave this blank (use MinimumValue and MaximumValue columns).
MinimumValue: If the variable is numeric, list the Minimum possible value. For example, if you expect a variable to be between 0-100, write 0 for MinimumValue. If there is no minimum value, leave this blank.
MaximumValue: If the variable is numeric, list the Maximum possible value. For example, if you expect a variable to be between 0-100, write 100 for MaximumValue. If there is no maximum value, leave this blank.
Comments: Additional notes such as exclusion criteria, reasons for special values, etc.
VariableName, Title, and Description are always required and cannot be left blank for data dictionary upload; every row in the data dictionary must have a VariableName, Title, and Description. The other columns are optional for upload, but are required for dataset publication.
Metadata refers to "data about the data" or information that may not constitute the data itself but provides an understanding of different aspects of the data. For instance, keywords associated with a dataset or the date on which a dataset was uploaded to a repository can be considered part of the metadata along the data. There are different types of metadata depending on their goal. A data dictionary, as described below, can be considered descriptive metadata that provides definitions and other elements for the content of a dataset. The citation of a dataset (similar to the citation of a paper) provides referencing metadata, and a data reuse license may provide legal metadata. Using standardized metadata increases the Findability and Interoperability of the data resources. The ODCs utilize the following standards.
ORCID. The ODCs support the Open Researcher and Contributor ID or ORCID, a researcher global standard identifier. Users can link their ODCs accounts and profiles to ORCID and use it for identification.
RRIDs. The ODCs support the use of Research Resource Identifiers or RRIDs, a standard identification number for the catalog of scientific tools and resources.
ODC-SCI: SCR_016673
ODC-TBI: SCR_021736
Creative Commons License. All datasets published on the ODC are under the Creative Commons Attribution License (CC-BY 4.0).
ODC Data dictionary. A data dictionary or codebook provides information about the dataset variables. It is one of the most important pieces of information to include with a dataset for anyone who wants to interpret and reuse the data.
ODC narrative summary (abstract). ODC offers a metadata narrative and summary where data owners can provide information about the dataset. This information is unique to each dataset and is essential for archiving, interpretability, and reuse.
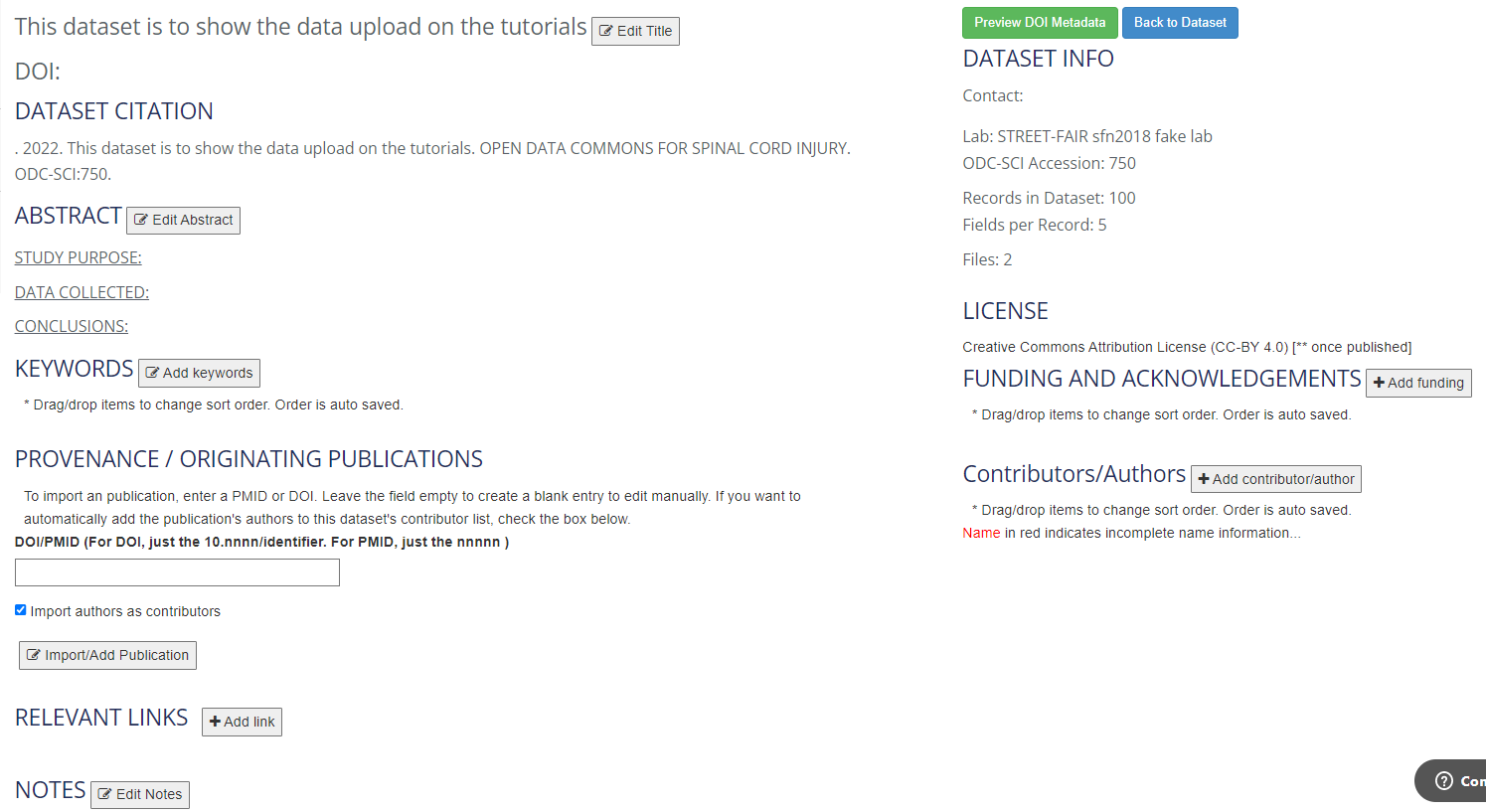
ODC offers a metadata form where you can provide information about the dataset in a standardized way. You can access the Metadata Editor for each dataset from a dataset view page. This information is unique to each dataset and helps with the interpretability and reuse of the data.
Title: Title that will be displayed on the dataset citation. Note that this will not change the title of the dataset visible within the ODC itself. Please include the species, sex, lesion type and area in your title.
Abstract: The Abstract includes 3 fields: Study Purpose, Data Collected, Data Usage Notes.
Study Purpose: Short description of the overall study purpose that resulted in the dataset.
Data Collected: Summary of what kind of data is included in the dataset and how the data was collected. Please include important experiment parameters (such as experimental model and injury severity) and critical outcome measures.
Conclusions: Summary of conclusions (if any) made with the dataset at the time of dataset publication.
Keywords: Keywords can be added to allow search engines to locate the DOI and dataset citation once the dataset is published. You can add your own keyword or start typing to see the ones ODC has already registered. You can reorder the keywords after they are added by dragging/dropping them in the list.
Provenance / Originating Publication: This section allows for entering publications that are related to the dataset. You can either import the information automatically or introduce it manually.
Import from existing publication: enter the DOI or PMID. Note that we can only import information from some preprint articles. Check the “Import authors as contributors” checkbox to import the publication’s author list automatically as contributors of the dataset (you will have to assign the dataset author and contact author labels to the respective entries after importing). After import, choose to edit the publication entry and fill out the remaining fields: Citation Relevance.
Manual: If you want to enter information manually, you can create a blank entry by leaving the DOI/PMID field blank and hitting “Import/Add Publication.” Choose to edit the new entry and fill out the appropriate fields: DOI, PMID, Citation, Citation Relevance.
Relevant links: This section allows for adding links to external resources that are relevant to the dataset. For example, if omics data associated to the dataset have been deposited in another repository, the link can be provided here. This section can also be used to link the current dataset to a published dataset in ODC.
Notes: The Notes section should be used to provide important guidance for others on using your data. Relevant information may include technical issues during the experiment that may require data exclusion, specifics about the techniques that may prevent merging with other datasets, and so on. The goal is to provide information useful to data re-users and prevent data misuse.
Funding and Acknowledgements: The Funding and Acknowledgements section requires 2 fields for each entry: Funding Agency, Funding Identifier and PI Initials. You can reorder the entries after they are added by dragging/dropping them in the list.
Funding Agency: Name of funding agency.
Funding Identifier and PI Initials: Respective funding ID (e.g. grant number) and PI Initials in parenthesis. For example: 4F0887Z (AC).
Contributors / Authors: ODC considers any Author of a dataset a Contributor. Authors will have their names attached to the citation of a dataset if published. Contributors that are not authors are other persons that do not constitute an author but you want acknowledge their contribution to the dataset. Each Contributor/Author has 5 fields to fill out. Each entry is added as a contributor to the dataset by default; if you check the options to include an entry as an author or contact author, the appropriate label will be applied to the contributor/author entry. Each entry includes: First Name, Middle Initial, Last Name, ORCID, Affiliation, and Contact Email (if contact author). Data that was imported might be incomplete and will need to be edited.
First Name: Person’s first name.
Middle Initial: Person’s middle initial (if relevant).
Last Name: Person’s last name.
ORCID: Person’s associated ORCID.
Affiliation: Person’s associated affiliation at time of publishing the dataset.
Contact Email: Person's contact email (field appears only if they are a contact author)
DOI: This is provided by ODC once you go through the DOI request process
Dataset Citation: This field provides you with a look at how the citation of the dataset will look like if released to the public. It is constructed automatically from the provided list of authors and the tile. You can see the changes as you change those two pieces of information!
Dataset Info: Dataset info is automatically populated from the other sections. The section includes: Contact Author information, Lab, ODC-SCI Accession Number, Number of Records in Dataset, Fields per Record, number of associated Files.
License: The License is automatically assigned once and if the dataset is published. All datasets published on the ODC-SCI will be under the Creative Commons Attribution License (CC-BY 4.0).