A data dictionary, also known as a codebook, provides information about the dataset variables. It is one of the most important pieces of information to include with a dataset for anyone who wants to interpret and reuse the data. Even if you are not planning on releasing your data, it is encouraged and of good data management practice to have data dictionaries for your datasets. You may know now what a variable name means in your spreadsheet (e.g., jtemp_6), but will your PI or colleagues know when you leave the lab? Will you know if you try to reuse the data two years from now? A data dictionary is a critical lab asset that ensures the data that have taken great effort and resources to acquire will not go to waste in the future due to poor documentation.
Data dictionaries can fulfill funding requirements for datasets to be accompanied with proper documentation
The data dictionary used by the ODC is a .csv file (a comma separated value file). Learn more about .csv files here.
Download the pre-clinical data dictionary template
The data dictionary file must contain the following column names in the first row:
VariableName: * Variables (i.e. column headers) that appear in the dataset. You must include all of your dataset variables in the data dictionary. Tip: Select your variable row in your dataset file and Copy, in the data dictionary file in cell A2, Paste Special>Transpose, all your variable names should be pasted into the first column of your data dictionary file now.
Title: * Title is the full name of the variable when the VariableName contains abbreviations or shorthand. If the VariableName is already a complete name, you can copy and paste the VariableName into the Title entry.
Unit_of_Measure: Units for the variable (if applicable).
Description: * Definitions and descriptions of the variable. The description should explain what the variable represents in enough detail such that a reader can understand the contents of the column in the dataset.
DataType: Specify whether the variable specifically contains Numeric, Categorical, Ordinal, Date, or Free Text data.
PermittedValues: If the variable is not numeric or free text, list all possible values here (e.g. "Male, Female" for the variable "Sex"). If the variable is numeric or free text, can leave this blank (use MinimumValue and MaximumValue columns).
MinimumValue: If the variable is numeric, list the Minimum possible value. For example, if you expect a variable to be between 0-100, write 0 for MinimumValue. If there is no minimum value, leave this blank.
MaximumValue: If the variable is numeric, list the Maximum possible value. For example, if you expect a variable to be between 0-100, write 100 for MaximumValue. If there is no maximum value, leave this blank.
Comments: Additional notes such as exclusion criteria, reasons for special values, etc.
VariableName, Title, and Description are always required and cannot be left blank for data dictionary upload; every row in the data dictionary must have a VariableName, Title, and Description. The other columns are optional for upload, but are required for dataset publication.
Currently for publishing datasets in the ODC-TBI only the unique identifier for subjects is required. Make sure your dataset contains the Subject_ID variable!
The ODC-SCI community has established a minimal set of variables that all pre-clinical datasets requesting a DOI, to be released to the public, must have.
We recommend for the first column of your dataset to have the name Subject_ID
If you get used to including these variables with the following names during the preparation of your data, you will reduce the time to get a DOI!
Please note that these requirements DO NOT apply to clinical datasets.
Subject_ID: Unique identifiers for each subject in the dataset
Species: Species of the subject
Strain: Strain of the subject
Animal_origin: Vendor or origin of the animal
Age: Age of the subject at start of experiment. If age is available at different timepoints, age is provided at the corresponding time in a corresponding time/timepoint variable
Weight: Weight of the subject at start of experiment. If weight is available at different timepoints, weight is provided at the corresponding time in a corresponding time/timepoint variable
Sex: Sex of the subject
Group: Name or identifier of the experimental group at which the subject was included if any
Laboratory: Name of laboratory, usually the PI
StudyLeader: Name of person responsible for overseeing project
Exclusion_in_origin_study: Whether the subject was included in the study that originated the data. 'Total exclusion" if excluded from the entire study, otherwise, specify experiment or measures of which the animal was excluded if any. For example: animals that were run in behavior but maybe tissue is loss and excluded from histological analyses. Reasons for exclusion might be specify in the exclusion_reason variable.
Exclusion_reason: Reason by which the subject was excluded from the study that originated the data as specified in the Exclusion_in_origin_study variable
Cause_of_Death: Cause of death (e.g. perfusion/necropsy, died during surgery, euthanized for health reasons, etc)
Injury_type: Type or model of injury used in the subject (e.g. contusion, complete transaction, partial section)
Injury_device: Name of the device used for the injury
Injury_level: Spinal cord level at which the injury was performed including segment (e.g. cervical; C) and number (e.g. C5)
Injury_details: Other details referent to the injury that might be relevant to understand the severity and type of injury performed
This page will teach you how to get your data ready for upload
If your dataset is already in ODC format, go to Upload Data
To upload data to the ODC we recommend you gather the information you need first! You will also be able to change things as you go, but having everything ready can help make the process easier. This page would guide you through the process of preparing your data.
If you are going to request a DOI for a public release, check this first!
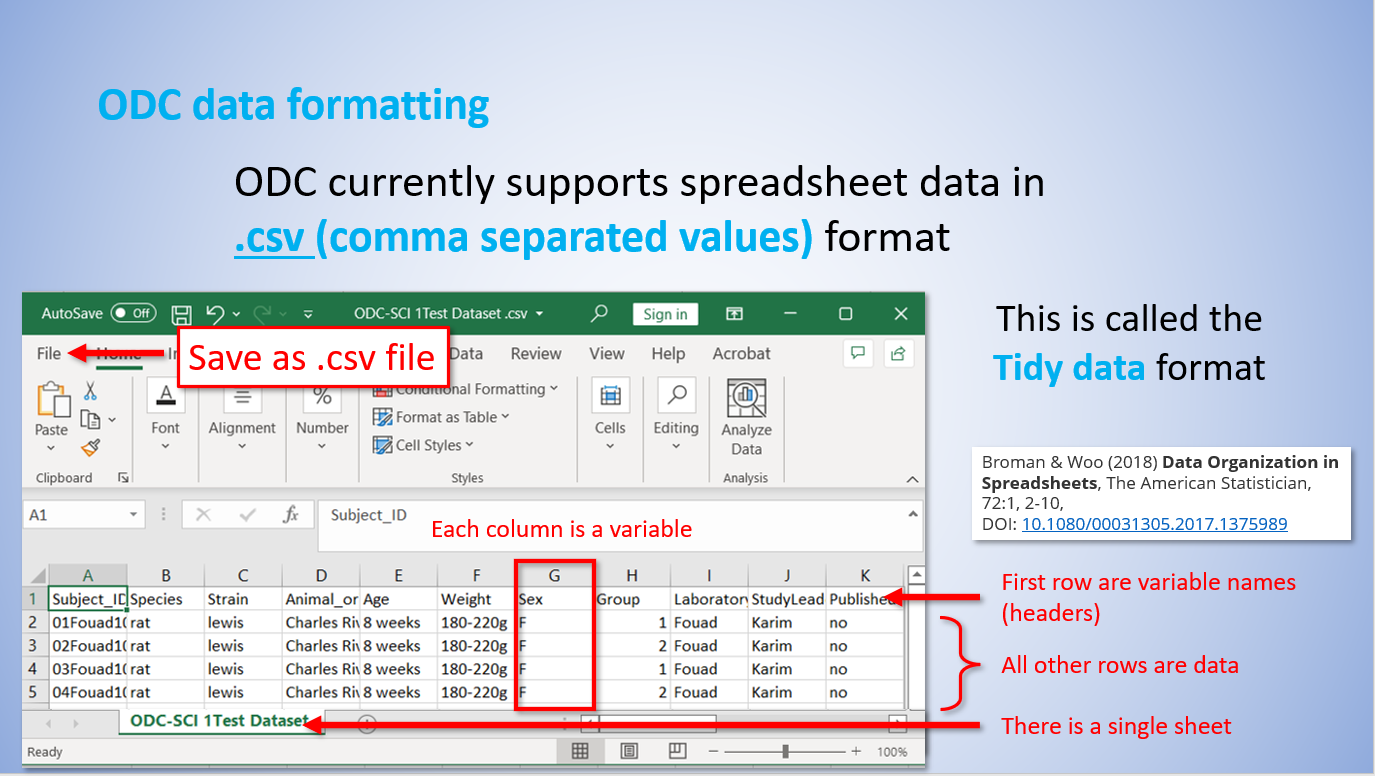
ODC supports uploading spreadsheet data in .csv (comma-separated values) file format. You can save your data to .csv format using the most common spreadsheet software, such as Excel.
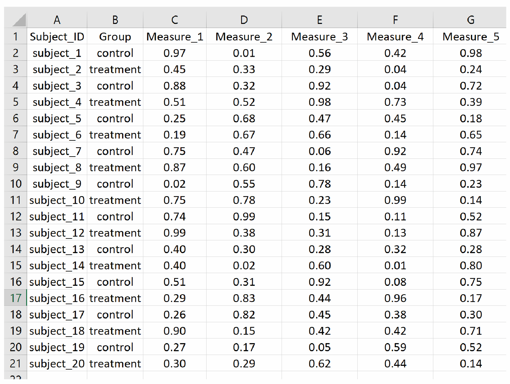
ODC uses tidy formatting of a spreadsheet or tabular data. The basics are simple: each row is an observation, and each column is a measure, field, or variable. A tidy data format is a great way to make data shareable and understandable by humans and machines!
The following two images illustrate how to create a .csv file with data organized in the tidy format.
Unique subject ID column: ODC is organized around subjects. One of your dataset columns must contain the subject or animal identifier (e.g. Subject_ID). This identifier should be unique for each subject. If subject_1 represents two different animals present in two different experiments, the identifier is not unique.
Columns as Variables: Each column represents a study parameter, outcome measure, field or variable
First row lists the Variable names: The first row of the dataset contains the name of the columns.
Subsequent rows as observations: Each row represents a single observation for a single subject.
A subject could have multiple rows. For example, your dataset might include multiple timepoints for each subject, in which case each row might represent a unique observation of a subject at a specific time point. The Subject ID column will help identify all the data for each specific subject in the dataset.
Column/Variable name requirements (based on best practices):
Keep variable names short. Avoid variable names longer than 60 characters.
Variable names must start with a letter.
Variable names should be intuitive (e.g. use “Date_Birth” instead of “DB”).
Avoid spaces in variable names. Use underscore (“_”) instead.
Avoid special characters except underscores (“_”) and periods (“.”). If you must use special characters, verify the corresponding Variable and data are uploaded correctly.
No duplicated Variable names: Every column header must have a unique name. If two of your columns have the same name, you will receive an error during data upload.
Avoid the use commas: CSV files use commas to separate the contents of one cell from another. If you use commas in a cell, it may be read as a delimiter character (i.e. cell separator) which can lead to errors in data upload. If you must use commas, always double check that your data is uploaded correctly. Microsoft Excel can also save csv's in such a way to prevent misinterpretation of commas in your data. However, we generally recommend avoiding the use of commas in your dataset altogether.
If you want to know more about .csv files
Want to know more about tidy data?
In ODC, the dataset and the data dictionary undergo quality checks for proper formatting (based on goodTables framework). These checks ensure that the data is Interoperable and Reusable with other datasets. Some of the quality checks are performed during the uploading of datasets, ensuring a minimal level of quality to all private and public datasets in the ODC-SCI. The check during the upload process is automatic without human oversight since data upload is handled privately within the account of the data owner. When data is released to the Community data space or submitted for publication, further checks will be conducted to ensure that the released or published dataset meets FAIR standards:
Source errors (Checked at upload): ODC-SCI can not read the data file. Possible reasons include:
The data file is not a *.csv. The ODC only accepts upload of *.csv data files.
Reserved special characters were used in the column headers (first row with the variable names). Check our recommendations for How to upload data.
Structure errors:
Blank-header (Checked at upload): There is a blank variable name. All cells in the header row (first row) must have a value.
Duplicate-header (Checked at upload): There are multiple columns with the same name. All column names must be unique.
Blank-row (Checked at upload): Rows must have at least one non-blank cell.
Duplicate-row: Rows can not be duplicated.
Schema errors: In ODC-SCI the schema is marked by the data dictionary. These errors reflect conflicts between the data dictionary and the dataset.
Extra-header: The dataset contains at least one variable name not defined in the data dictionary.
Missing-header: The dataset is missing at least one variable name defined in the data dictionary.
Missing-definition: The definition of a variable in the data dictionary is missing.
Required-constraint (Checked at upload): A required field for the dataset contains no values or is not assigned on the dataset. Currently the only required value in the datasets is the subject identifier. As ODC-SCI develops additional data standards, it is possible that more variables will be required on all datasets.
Value-constraint: The values of a variable should be equal to one of the permitted values enumerated in the data dictionary, or within the limits of the permitted values.